The latest version of this text can be found at https://info340.github.io/.
Chapter 2 Client-Side Development
Web development is the process of implementing (programming) web sites and applications that users can access over the internet. However, the internet is a network involving many different computers all communicating with one another. These computers can be divided into two different groups: servers store (“host”) content and provide (“serve”) it to other computers, while clients request that content and then present it to the human users.
Consider the process of viewing a basic web page, such as the Wikipedia entry on Informatics. In order to visit this page, the user types the web address (https://en.wikipedia.org/wiki/Informatics) into the URL bar, or clicks on a link to go to the page. In either case, the user’s computer is the client, and their browser takes that address or link and uses it to create an HTTP Request—a request for data sent following the HyperText Transfer Protocol. This request is like a letter asking for information, and is sent to a different computer: the web server that contains that information.
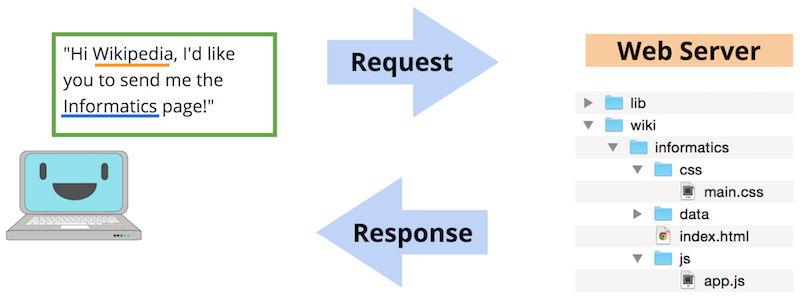
A diagram of client/server communication.
The web server will receive this request, and based on its content (e.g., the parameters of the URL) will decide what information to send as a response to the client. In general, this response will be made up of lots of different files: the text content of the web page, styling information (font, color) for how it should look, instructions for responding to user interaction (button clicks), images or other assets to show, and so forth.
The client’s web browser will then take all of these different files in the response and use them to render the web page for the user to see: it will determine what text to show, what font and color to make that text, where to put the images, and is ready to do something else when the user clicks on one of those images. Indeed, a web browser is just a computer program that is able to send HTTP requests on behalf of the user, and then render the resulting response.
Given this interaction, client-side web development involves implementing programs (writing code) that are interpreted by the browser, and are executed by the client. It is authoring the code that is sent in the server’s response. This code specifies how websites should appear and how the user should interact with them. On the other hand, server-side web development involves implementing programs that the server uses to determine which client-side code is delivered. As an example, a server-side program contains the logic to determine which cat picture should be sent along with the request, while a client-side program contains the logic about where and how that picture should appear on the page.
This course focuses on client-side web development, or developing programs that are executed by the browser (generally as a response to a web server request). While we will cover how client-side programs can interact with a server, many of the concepts discussed here can also be run inside a browser without relying on an external server (called “running locally”, since the code is run on the local machine).
2.1 Client-Side File Types
It is the web browser’s job to interpret and render the source code files sent by a server as part of an HTTP response. As a client-side web programmer, your task is to write this source code for the browser to interpret. There are multiple different types of source code files, including:
.htmlfiles containing code written in HTML (HyperText Markup Language). This code will specify the textual and semantic content of the web page. See the chapter HTML Fundamentals for details on HTML..cssfiles containing code written in CSS (Cascading Style Sheets). This code is used to specify styling and visual appearance properties (e.g., color and font) for the HTML content. See the chapter CSS Fundamentals for details on CSS..jsfiles containing code written in JavaScript. This code is used to specify interactive behaviors that the website will perform—for example, what should change when the user clicks a button. Note that JavaScript code are “programs” that sent over by the web server as part of the response, but are executed on the client’s computer. See the chapter JavaScript Fundamentals for details on JavaScript.
HTTP responses may also include additional asset files, such as images (.png, .jpg, .gif, etc), fonts, video or music files, etc.
2.2 HTTP Requests and Servers
Modern web browsers are able to render (interpret and display) all of these types of files, combining them together into the modern, interactive web pages you use every day. In fact, you can open up almost any file inside a web browser, such as by right-clicking on the file and selecting “Open With”, or dragging the file into the browser program. HTML files act as the basis for web pages, so you can open a .html file inside your web browser by double-clicking on it (the same way you would open a .docx file in MS Word):
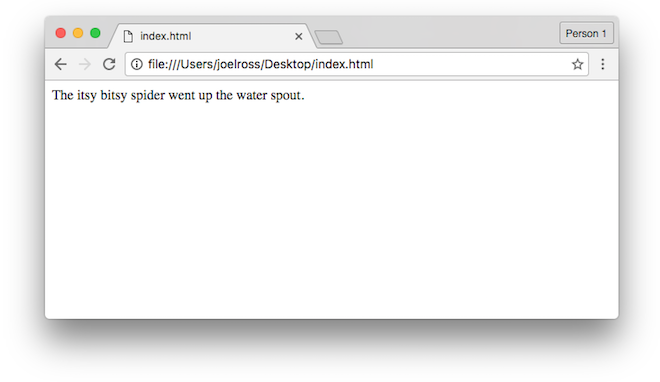
An very simple HTML file. See Chapter 3 for source code.
Consider the URL bar in the above browser. The URL (Uniform Resource Locator) is actually a specialized version of a URI (Uniform Resource Identifier). URIs act a lot like the address on a postal letter sent within a large organization such as a university: you indicate the business address as well as the department and the person, and will get a different response (and different data) from Alice in Accounting than from Sally in Sales.
- Note that the URI is the identifier (think: variable name) for the resource, while the resource is the actual data value (the file) that you want to access.
Like postal letter addresses, URIs have a very specific format used to direct the request to the right resource.

The format (schema) of a URI.
The parts of this URI format include:
scheme(alsoprotocol): the “language” that the computer will use to send the request for the resource (file).In the example browser window above, the protocol is
file, meaning that the computer is accessing the resource from the file system. When sending requests to web servers, you would usehttps(secure HTTP). Don’t use insecurehttp!Web page hyperlinks often include URIs with the
mailtoprotocol for email links, or thetelprotocol for phone numbers.domain: the address of the web server to request information from. You can think of this as the recipient of the request letter.In the browser window example, there is no domain because the
fileprotocol doesn’t require it, but for most web URIs this would be the address (e.g.,google.comorischool.uw.edu).port(optional): used to determine where to connect to the web server. By default, web requests use port80, but some web servers accept connections on other ports—e.g.,8080,8000and3000are all common on development servers, described below.path: which resource on that web server you wish to access. For thefileprotocol, this is the absolute path to the file on your computer. But even when usinghttps, for many web servers, this will be the relative path to the file, starting from the “root” folder of that server (which may not be the computer’s root folder). For example, if a server used/Users/joelross/as its root, then the path to the above HTML file would beDesktop/index.html(e.g.,https://domain/Desktop/index.html).Important! If you specify a path to a folder rather than a file (including
/as the “root” folder), most web servers will serve the file namedindex.htmlfrom that folder (i.e., the path “defaults” toindex.html). As such, this is the traditional name for the HTML file containing a website’s home page.As in any program, you should always use relative paths in web programming, and these paths are frequently (but not always!) relative to the web server’s root folder.
query(optional): extra parameters (arguments) included in the request about what resource to access. The leading?is part of the query.fragment(optional): indicates which part (“fragment”) of the resource to access. This is used for example to let the user “jump” to the middle of a web page. The leading#is part of the fragment.
Development Servers
As noted above, it is possible to request a .html file (open a web page) using the file protocol by simply opening that file directly in the browser. This works fine for testing many client-side programs. However, there are a few client-side interactions that for security reasons only work if a web page is requested from a web server (e.g., via the http or https protocol).
For this reason, it is recommended that you develop client-side web applications using a local development web server. This is a web server that you run from your own computer—your machine acts as a web server, and you use the browser to have your computer send a request to itself for the webpage. Think of it as mailing yourself a letter. Development web servers can help get around cross-origin request restrictions, as well as offer additional benefits to speed development—such as automatically reloading the web browser when the source code changes.
There are many different ways to run a simple development server from the command line (such as using the Python http.server module). These servers, when started, will “serve” files using the current directory as the “root” folder. So again, if you start a server from /Users/joelross, you will be able to access the Desktop/index.html file at http://127.0.0.1:port/Desktop/index.html (which port will depend on which development server you use).
The address
127.0.0.1is the IP address forlocalhostwhich is the domain of your local machine (the “local host”). Most development servers, when started, will tell you the URL for the server’s root directory.Most commonly, you will want to start the web server from the root directory of your project, so that the relative path
index.htmlfinds the file you expect.You can usually stop a command line development server with the universal
ctrl + ccancel command. Otherwise, you’ll want to leave the server running in a background terminal as long as you are working on your project.
If you use the recommended live-server utility, it will open a web browser to the root folder and automatically reload the page whenever you save changes to a file in that folder. This will make your life much, much better.